Research Interest
- large language model;
- video generative / video editing models;
- vision-and-language, multi-modal learning.
Iconzheyuan.david.liu [at] outlook.com
I am a Senior Applied Scientist at Oracle Health AI (OHAI), applying generative AI to the medical domain.
Previously, I was a research fellow at the Centre for Augmented Reasoning, Australian Institute for Machine Learning (AIML) at the University of Adelaide, working with Prof. Anton Van Den Hengel on video generative models.
I obtained my PhD from the Australian National University in 2024, advised by Prof. Stephen Gould and Dr. Damien Teney (Idiap Research Institute | AIML). My PhD surrounds multi-modal learning, vision-and-language, where I focused on the task of composed image retrieval.
I maintain my publication record at Google Scholar. Source code for all first-author projects are available at GitHub.
Sep 2025 I have joined Oracle Health AI as a Senior Applied Scientist.
May 2024 I have joined AIML as a postdoctoral research fellow.
Apr 2024 I have received my award of PhD from ANU. A big thank you to my supervisors, my parents and all my friends for their kind support through this journey.
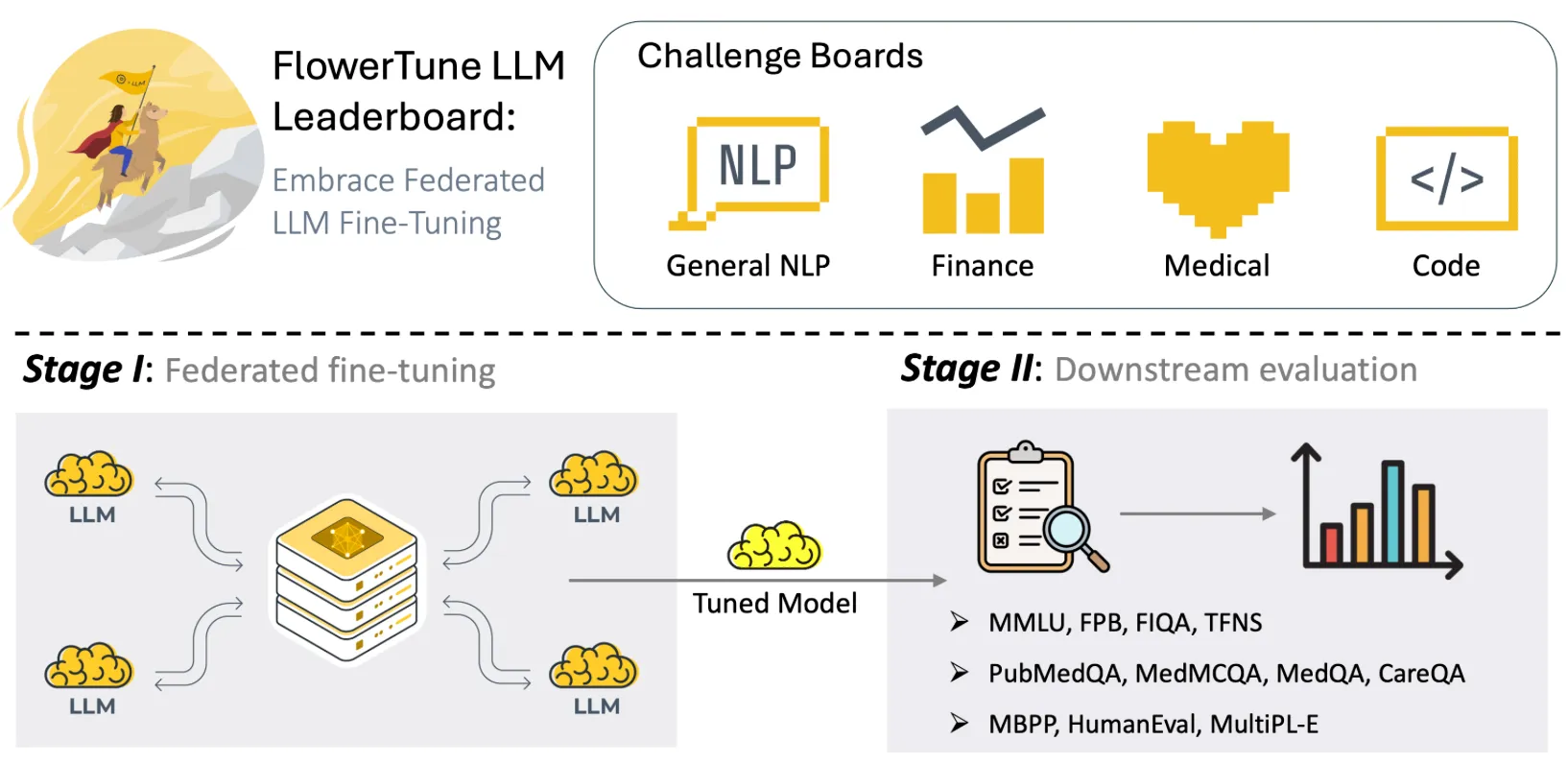
FlowerTune: A Cross-Domain Benchmark for Federated Fine-Tuning of Large Language Models.
The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025.
@inproceedings{gao2025flowertune,
title={FlowerTune: A Cross-Domain Benchmark for Federated Fine-Tuning of Large Language Models},
author={Yan Gao and Massimo Roberto Scamarcia and Javier Fernandez-Marques and Mohammad Naseri and Chong Shen Ng and Dimitris Stripelis and Zexi Li and Tao Shen and Jiamu Bai and Daoyuan Chen and Zikai Zhang and Rui Hu and InSeo Song and Lee KangYoon and Hong Jia and Ting Dang and Junyan Wang and Zheyuan Liu and Daniel Janes Beutel and Lingjuan Lyu and Nicholas D. Lane},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2025},
url={https://openreview.net/forum?id=l8Nb6ecZjW}
}
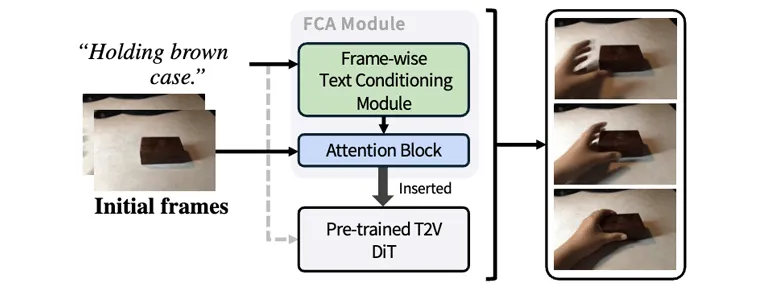
Frame-wise Conditioning Adaptation for Fine-Tuning Diffusion Models in Text-to-Video Prediction.
Transactions on Machine Learning Research (TMLR), 2025.
@article{liu2025framewise,
title={Frame-wise Conditioning Adaptation for Fine-Tuning Diffusion Models in Text-to-Video Prediction},
author={Zheyuan Liu and Junyan Wang and Zicheng Duan and Cristian Rodriguez-Opazo and Anton van den Hengel},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2025},
url={https://openreview.net/forum?id=HSAjl4LUHK},
note={}
}

OpenKD: Opening Prompt Diversity for Zero- and Few-shot Keypoint Detection.
European Conference on Computer Vision (ECCV), 2024.
@inproceedings{lu2025openkd,
title={OpenKD: Opening Prompt Diversity for Zero-and Few-shot Keypoint Detection},
author={Lu, Changsheng and Liu, Zheyuan and Koniusz, Piotr},
booktitle={European Conference on Computer Vision},
pages={148--165},
year={2025},
organization={Springer}
}
Retrieving Images through Bi-modal Visual and Language Queries.
Thesis (PhD), Australian National University, 2024.
@phdthesis{liu2024retrieving,
title={Retrieving Images through Bi-modal Visual and Language Queries},
author={Liu, Zheyuan},
school={The Australian National University},
year={2024}
}
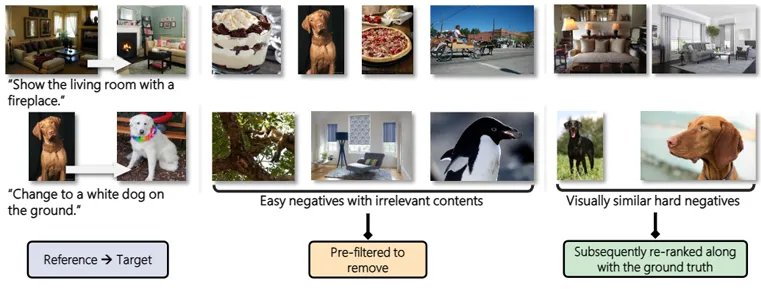
Candidate Set Re-ranking for Composed Image Retrieval with Dual Multi-modal Encoder.
Transactions on Machine Learning Research (TMLR), 2024.
@article{liu2024candidate,
title={Candidate Set Re-ranking for Composed Image Retrieval with Dual Multi-modal Encoder},
author={Zheyuan Liu and Weixuan Sun and Damien Teney and Stephen Gould},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=fJAwemcvpL},
note={}
}

Bi-Directional Training for Composed Image Retrieval via Text Prompt Learning.
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2024.
@InProceedings{Liu_2024_WACV,
author={Liu, Zheyuan and Sun, Weixuan and Hong, Yicong and Teney, Damien and Gould, Stephen},
title={Bi-Directional Training for Composed Image Retrieval via Text Prompt Learning},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month={January},
year={2024},
pages={5753-5762}
}

All-pairs Consistency Learning for Weakly Supervised Semantic Segmentation.
IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, 2023.
@InProceedings{Sun_2023_ICCV,
author={Sun, Weixuan and Zhang, Yanhao and Qin, Zhen and Liu, Zheyuan and Cheng, Lin and Wang, Fanyi and Zhong, Yiran and Barnes, Nick},
title={All-pairs Consistency Learning forWeakly Supervised Semantic Segmentation},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops},
month={October},
year={2023},
pages={826-837}
}
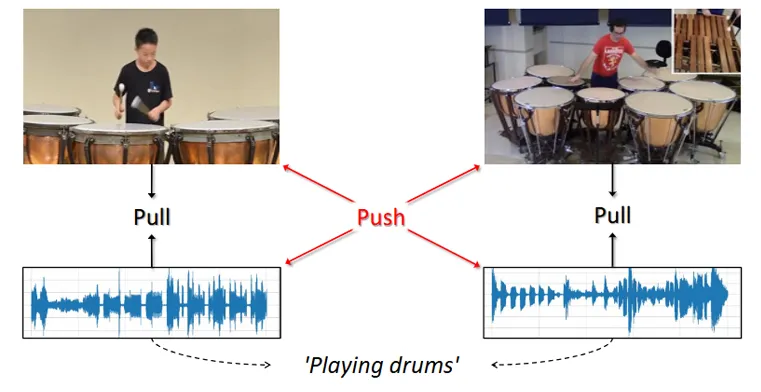
Learning Audio-Visual Source Localization via False Negative Aware Contrastive Learning.
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
@InProceedings{Sun_2023_CVPR,
author={Sun, Weixuan and Zhang, Jiayi and Wang, Jianyuan and Liu, Zheyuan and Zhong, Yiran and Feng, Tianpeng and Guo, Yandong and Zhang, Yanhao and Barnes, Nick},
title={Learning Audio-Visual Source Localization via False Negative Aware Contrastive Learning},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month={June},
year={2023},
pages={6420-6429}
}

Image Retrieval on Real-Life Images With Pre-Trained Vision-and-Language Models.
IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
@InProceedings{Liu_2021_ICCV,
author={Liu, Zheyuan and Rodriguez-Opazo, Cristian and Teney, Damien and Gould, Stephen},
title ={Image Retrieval on Real-Life Images With Pre-Trained Vision-and-Language Models},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month={October},
year={2021},
pages={2125-2134}
}